サイバーエージェントさんが「DeepSeek-R1」を日本語でのチューニングを強化したローカルAIデータを公開しています。このファイルを使えばノートPCで、インターネット接続なしでAIが使えるようになります。
サイバーエージェントさんが「DeepSeek-R1」を日本語でのチューニングを強化したローカルAIデータを公開しています。このファイルを使えばノートPCで、インターネット接続なしでAIが使えるようになります。
つまり「ローカルAI」が実現できるのですが、このローカルAIが「推論できるR1」ならかなり強力です。実際に私の非力なノートPCで動くかどうかを試してみました。
ノートPC内にローカルAI環境を作りました
そもそもローカルAIとは
ローカルAI、特にローカルLLM(Local Language Model)とは、インターネットに接続せずに、個人のデバイスや企業のサーバーなどのローカル環境で動作するAI技術です。主な特徴は以下の通りです。
- インターネット接続不要: オフラインで利用可能で、ネットワーク環境に左右されません。
- セキュリティの強化: データを外部に送信せず、ローカル環境内で処理するため、情報漏洩のリスクが低減され、プライバシーが保護されます。
- カスタマイズ性とコスト削減: 自社のデータでAIを調整でき、長期的にはコストを抑えることができます。
「Ollama」を使うか、「LM Studio」を使うか
ローカルAIを設定する方法としては、「Ollama」を使うか、「LM Studio」を使うか、大きくはこの2択です。私の非力なノートPCで「DeepSeek-R1-Distill-Qwen-14B-Japanese」を使うとしたらどちらがいいか?
ちなみに、私のノートパソコンは昨年末に調達したマウスコンピューターの「mouse A4-A5U01SR-B」です。基本の商品価格は89800円(税込)とお安いですが、少しスペック増強してあります。
■OS Windows 11 Pro 64ビット
■CPU AMD Ryzen 5 7430U プロセッサ ( 6コア / 12スレッド / 2.3GHz / 最大4.3GHz / L3キャッシュ 16MB )
■メモリ 32GB メモリ [16GB×2 ( DDR4-3200 ) / デュアルチャネル ]
■SSD (M.2) 1TB NVM Express SSD ( M.2 PCI Express 接続 )
このスペックならローカルAIの導入ができそうです。おそらくぎりぎりの性能ですが…(笑)
「LM Studio(エルエムスタジオ)」を使うことにしました
Perplexityで検討を進めた結果、文章記述活用が多いのなら「LM Studio」のほうが良さそうということがわかりました。
「LM Studio」のインストール手順は以下のとおりです。
- LM Studioのダウンロード
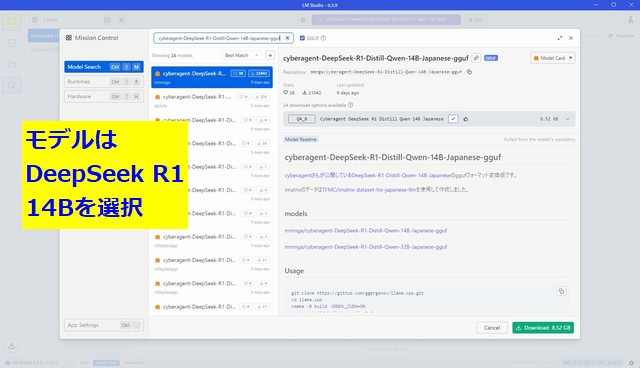
- モデルの選択
- 検索バーで「DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf」を選択
- モデルの実行
- ダウンロード後「Load Model」をクリックし選択し実行する

| 項目 | Lightblue 7B | サイバーエージェント 14B/32B※ |
|---|---|---|
| 推奨環境 | Ryzen5000 + 32GB RAM | GPU搭載マシン推奨 |
| ダウンロード先 | Hugging Face | Hugging Face |
| 量子化版 | GGUFフォーマット提供 | 未対応 |
| 応答速度 | 25-35トークン/秒 | 10-15トークン/秒 |
※「DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf」には「量子化版」がないようです。「量子化版」だと回答速度が早いということでしたが、今後なんらかの高速化対応がされるといいですね。
ここまでは意外にすんなりと行けました。表示言語は英語でしたが、日本語に変更することもできます。AIモデルも複数から選択可能でした。けっこう便利そうです。
このAIは優秀な回答をしてくれますが…ちょっと遅いです
実際にいくつかの質問をし回答を得ました。回答の精度はなかなかよいです。しかし、考えている時間が長いです。また回答を表示するのにもけっこうな時間がかかりました。回答が遅いのがネックです。
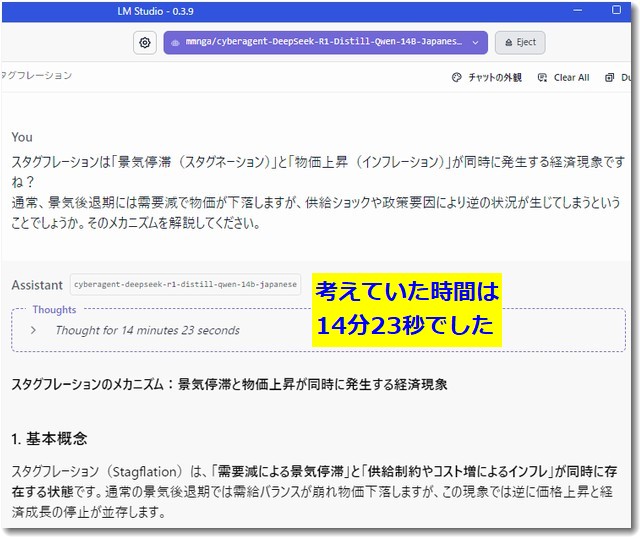
上記は「スタグフレーション」についての質問ですが、考えていた時間が14分23秒です。そして回答も長いので書き終えるまでに5分以上かかったと思います。
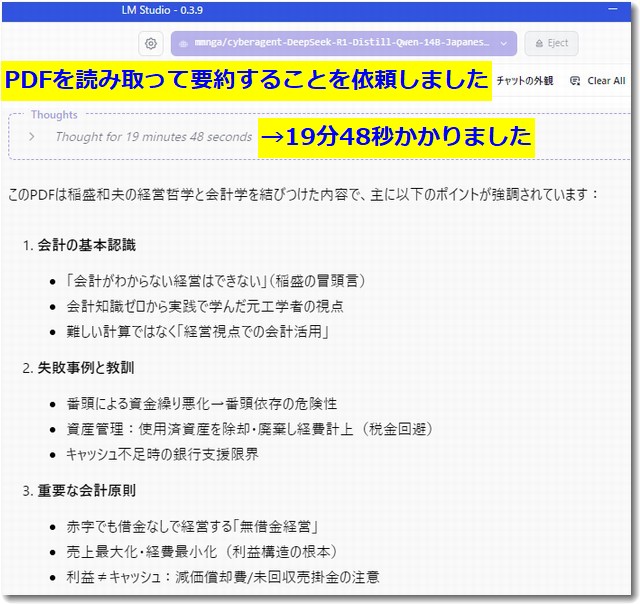
PDFを読み込ませてその要約をしてもらうこともできました。上記の場合は考えている時間が19分48秒でした。
つまり質問を入力してから回答が表示し終えるまで20分以上かかるということです。これは一例ですが、こんな感じだと利用頻度が下がりますね。
回答は悪くないし、インターネットに接続していないので入力したデータが外部のサーバーに行かないのでセキュリティは安心です。しかし、これは遅い、遅すぎる。
そこで、もう少し回答が早くならないかどうかを検討しました。
回答を早くするためのチューニング例
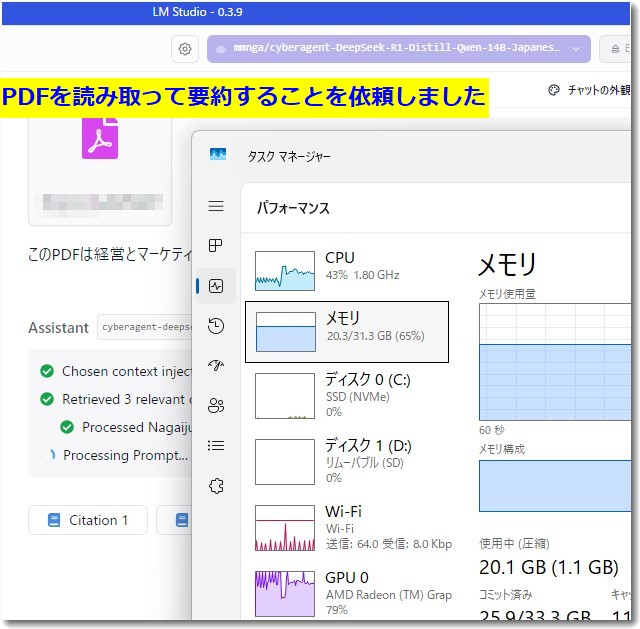
LM Studioが動いているときは、メモリが20GBくらい利用されています。またCPUも40%程度、GPUも80%とかなりの稼働率です。これだけ忙しい状況でも回答までには長い時間がかかります。
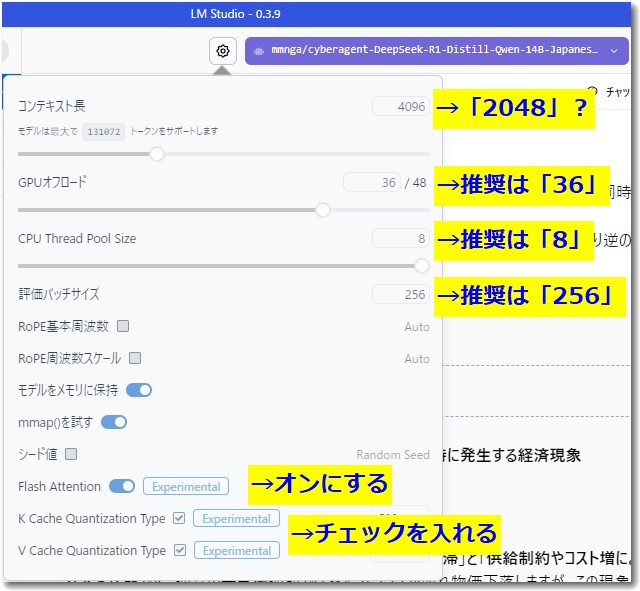
そこでLM Studioの設定変更で回答速度を向上させることにチャレンジしました。以下はPerplexityで調べた結果、高速化のために推奨された設定変更の例です。
- GPU Offload
- 現在の設定:0/48
- 推奨設定:35-45程度に増やす
- 効果:GPUの処理能力を最大限活用できます
- Context Length
- 現在の設定:4096
- 推奨設定:2048に減らす
- 効果:処理負荷を軽減できます
- CPU Thread Pool Size
- 現在の設定:4
- 推奨設定:8-16(CPUのコア数に応じて)
- 効果:CPU処理の並列化が向上します
- Evaluation Batch Size
- 現在の設定:512
- 推奨設定:256または128に減らす
- 効果:メモリ使用量を抑えつつ、応答速度が向上します
- その他の最適化設定
- Flash Attention:Experimentalを有効化
- Keep Model in Memory:ONに設定
- Try mmap:ONに設定
これらの設定を適用することで、現在の応答時間を大幅に短縮できる可能性があります。特にGPU Offloadの設定を上げることが最も効果的です。
ということなのでこのアドバイスに沿って設定を少し変更しました。
実際には、このあともいくつかの数値を変更することで、回答時間は少し早くなりました。運用しながら、微調整していこうかと思います。
ローカルAI専用のマシンも検討ですね
ですが、抜本的に回答速度を改善するには、マシンスペックをアップグレードシないと無理でしょうね。例えば将棋の藤井聡太さんが使っているようなGPU内臓のコンピュータなら実用速度になるかもしれません。

かなりのハイスペックマシンです。

たしか新車1台分くらいは軽くするような価格だった記憶があります。
PerplexityのDeepResearchで調べてみました。

回答の結果は最低でも100万円台でハイエンド構成なら500万円超ということでした。
AMD Ryzen Threadripper PROを中核とするAIワークステーションの価格帯は、エントリーモデルで100万円台から、藤井聡太氏クラスのハイエンド構成で500万円超まで多岐にわたる。価格対性能比では、64コア5995WX搭載システムがバランス型ソリューションとして優位性を示すが、将来性を考慮すれば96コア7995WXへの投資も合理性を持つ。企業導入に際しては、AMD PROのセキュリティ機能とリモート管理機能がTCO削減に寄与する点を評価すべきである。
なかなかのスペックと費用になりますね。
LM Studioは商用利用に制限がありますのでご注意を
LM Studioは個人での非商用利用は無料です。実験的にいろんなことを試すのはOKです。
しかし、商用利用にはいくつかの制限があります。LM Studioの無料利用条件は公式規約と関連情報から以下のように整理できます。いちおう確認しておきましょう。
基本条件
- 個人利用に限定:非営利目的での使用に限り無料
- データ収集なし:全ての処理がローカルで完結
- オフライン動作保証:インターネット接続不要(モデルダウンロード後)
技術的要件
| プラットフォーム | 最低要件 |
|---|---|
| macOS | M1/M2/M3チップ・macOS 13.4以上・16GB RAM推奨 |
| Windows/Linux | AVX2対応CPU・16GB RAM推奨 |
主な制限事項
商用利用禁止企業内利用・顧客向けサービス組み込み不可業務でのプロトタイピングも規制対象
- 再配布制限
- ソフトウェアの改変・再頒布不可
- ロゴ/商標の無断使用禁止
- 使用方法の制約
text
- クラウドサーバーでのホスティング不可[1]
- 自動化スクリプトによる大量アクセス禁止[1]
- 逆コンパイル/逆アセンブル行為の禁止[1]
2025年7月10日のニュースで朗報です。LMスタジオの商用利用が解禁になりました。
ローカルLLMのフロントエンドアプリ「LM Studio」を提供する米Element Labsは7月8日(現地時間)、企業や組織での「LM Studio」を無料化すると発表した。個人利用は従来から無料だったが、企業利用では同社への連絡と別途ライセンス取得が必要だった。商用ライセンスの取得手続きを廃止し、手軽に業務利用できるようにする。
モデル利用に関する注意点
- ダウンロードモデルのライセンスは各配布元が管理
- 例:Meta Llama 3は商用可能だがLM Studio経由では規約適用
- モデルファイルの二次配布禁止
違反時の対応
- ライセンス自動終了
- 法的措置の可能性
- アカウント停止(存在する場合)
無料利用の範囲内でも、研究・教育目的での使用は可能ですが、学術機関での業務利用は商用とみなされます。ハードウェア要件を満たしていれば、個人開発者がOSSモデルを試す用途で自由に利用可能です。
#LMStudio #LMスタジオ #LM studio

この記事を書いた遠田幹雄は中小企業診断士です
遠田幹雄は経営コンサルティング企業の株式会社ドモドモコーポレーション代表取締役。石川県かほく市に本社があり金沢市を中心とした北陸三県を主な活動エリアとする経営コンサルタントです。
小規模事業者や中小企業を対象として、経営戦略立案とその後の実行支援、商品開発、販路拡大、マーケティング、ブランド構築等に係る総合的なコンサルティング活動を展開しています。実際にはWEBマーケティングやIT系のご依頼が多いです。
民民での直接契約を中心としていますが、商工三団体などの支援機関が主催するセミナー講師を年間数十回担当したり、支援機関の専門家派遣や中小企業基盤整備機構の経営窓口相談に対応したりもしています。
保有資格:中小企業診断士、情報処理技術者など
会社概要およびプロフィールは株式会社ドモドモコーポレーションの会社案内にて紹介していますので興味ある方はご覧ください。
お問い合わせは電話ではなくお問い合わせフォームからメールにておねがいします。新規の電話番号からの電話は受信しないことにしていますのでご了承ください。

【反応していただけると喜びます(笑)】
記事内容が役にたったとか共感したとかで、なにか反応をしたいという場合はTwitterやフェイスブックなどのSNSで反応いただけるとうれしいです。
本日の段階で当サイトのブログ記事数は 7,088 件になりました。できるだけ毎日更新しようとしています。
遠田幹雄が利用しているSNSは以下のとおりです。
facebook https://www.facebook.com/tohdamikio
ツイッター https://twitter.com/tohdamikio
LINE https://lin.ee/igN7saM
チャットワーク https://www.chatwork.com/tohda

また、投げ銭システムも用意しましたのでお気持ちがあればクレジット決済などでもお支払いいただけます。
※投げ銭はスクエアの「寄付」というシステムに変更しています(2025年1月6日)
※投げ銭は100円からOKです。シャレですので笑ってご支援いただけるとうれしいです(笑)
株式会社ドモドモコーポレーション
石川県かほく市木津ロ64-1 〒929-1171
電話 076-285-8058(通常はFAXになっています)
IP電話:050-3578-5060(留守録あり)
問合→メールフォームからお願いします
法人番号 9220001017731
適格請求書(インボイス)番号 T9220001017731
英語表示の社名:DomoDomo Corporation Inc.