 LMスタジオで使うOpenAIのオープンソース版のChatGPTといわれている「gpt-oss-20b」。先週からあらたにunsloth版のモデルがダウンロードできるようになっていました。「unsloth」とは「アンスロース/遅くないよ!」という意味を持っています。非力なノートPCなので少しでも高速化できるといいなということでこのモデルを試してみました。
LMスタジオで使うOpenAIのオープンソース版のChatGPTといわれている「gpt-oss-20b」。先週からあらたにunsloth版のモデルがダウンロードできるようになっていました。「unsloth」とは「アンスロース/遅くないよ!」という意味を持っています。非力なノートPCなので少しでも高速化できるといいなということでこのモデルを試してみました。
ローカルAIのLMスタジオでチューニング
「gpt-oss-20b」にunsloth版モデルが追加されました
unsloth(Unsloth)は、LLM(大規模言語モデル)を速く・低メモリで微調整(ファインチューニング)できるオープンソースの開発フレームワーク/ツール群です。Apache-2.0ライセンスで無料利用でき、クラウド/商用向けの上位版もあります。
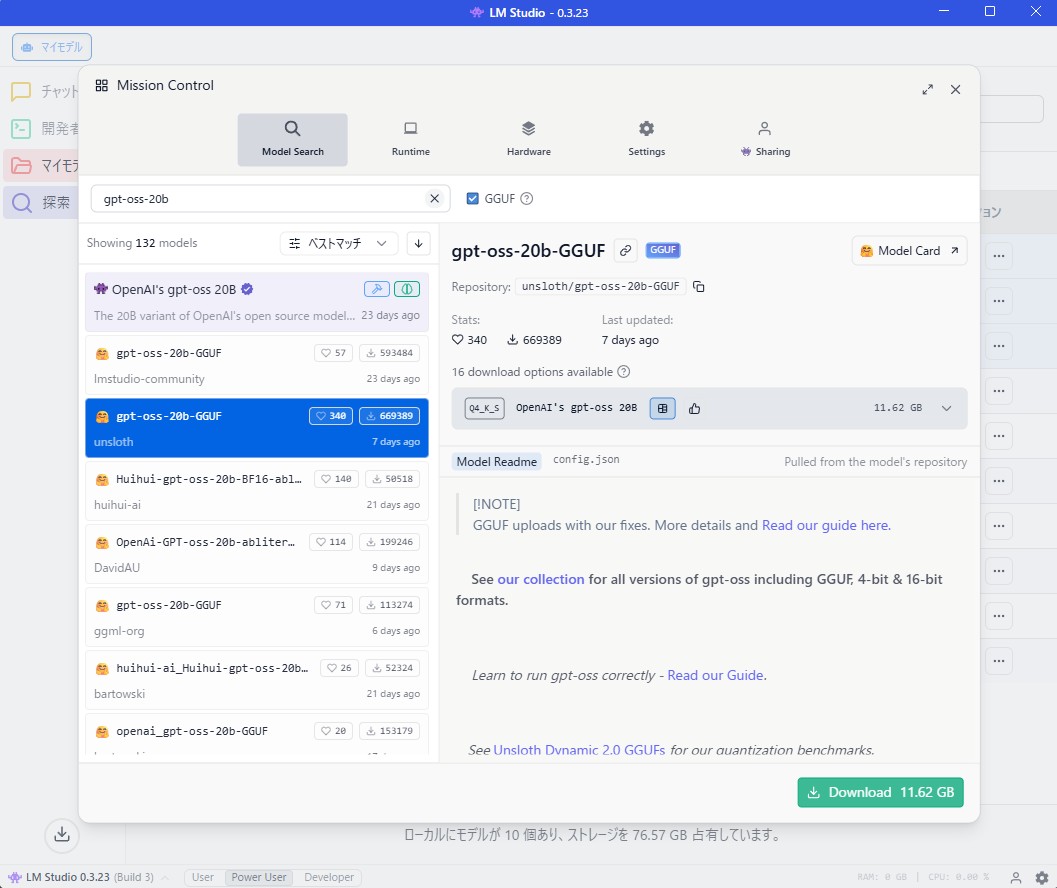
「gpt-oss-20b」にもUnslothモデルがでたのはうれしいです。これで「LM Studio(エルエムスタジオ)」でUnslothモデルの「gpt-oss-20b」が使えるようになりました。
LM Studioは、自分のPCで生成AIを使うための無料のアプリです。商用利用可能になったことで利用者が増えています。

上記の公式サイトからダウンロードできます。
さらなる高速化を目指すためのチューニング方法
私が使っているノートPC(Ryzen 5, 32GB RAM, 内蔵GPU)の性能を最大限に引き出すためには、以下の3つのステップで調整を進めるのがおすすめということでした。(Geminiで調査しました)
ステップ1:GPUオフロードの「最適点(スイートスポット)」を探す(最重要)
現在8層に設定している GPUオフロード は、まだ余裕がある可能性が高いです。
- 方法:
GPUオフロードのスライダーを 10層 に設定し、モデルを再読み込みしてパフォーマンス(応答速度)を確認します。- 問題なければ、次は 12層、14層…と2層ずつ増やしていきます。
- 応答生成時の速度(
tok/sec)が最も高くなる点、もしくはPCが不安定にならないギリギリの層数が、お使いのPCの「最適点(スイートスポット)」です。
内蔵GPUの性能によりますが、おそらく12〜18層あたりに最適点が見つかるかと思います。これが最も効果の大きいチューニングです。
ステップ2:プロンプトの読み込みを速くする
長い文章をAIに読み込ませた際の、最初の「考え込む時間」を短縮する設定です。
- 設定項目:
評価バッチサイズ(Evaluation Batch Size) - 現在の設定: 512
- 推奨設定: 1024 に変更してみてください。
RAMが32GBと十分にあるため、一度に処理するデータ量(バッチサイズ)を増やすことで、プロンプトの処理速度が向上する可能性があります。もし1024で問題なければ、2048を試す価値もあります。
ステップ3:AIの文章生成を速くする
AIが文章を生成する(単語を一つずつ紡ぎ出す)速度を向上させる設定です。
- 設定項目:
CPUスレッドプールサイズ(CPU Thread Pool Size) - 現在の設定: 4
- 推奨設定: 6 または 8 に変更してみてください。
Ryzen 5 7000シリーズのCPUは、少なくとも6つの物理コアを持っています。CPUスレッド数を物理コア数に近づけることで、GPUが担当しない部分の計算処理能力を最大限に引き出し、文章の生成が速くなります。
チューニング設定のまとめ
まずはステップ1のGPUオフロード層数の調整から始めて、最も効果が出る設定を見つけることをお勧めします。その後、ステップ2と3を調整することで、さらに快適な動作を目指せるということでした。
現在の詳細設定:gpt-oss-20b-GGUF
いろいろ調整した結果、出力が安定してそこそこの速さで表示される設定は以下のようになりました。
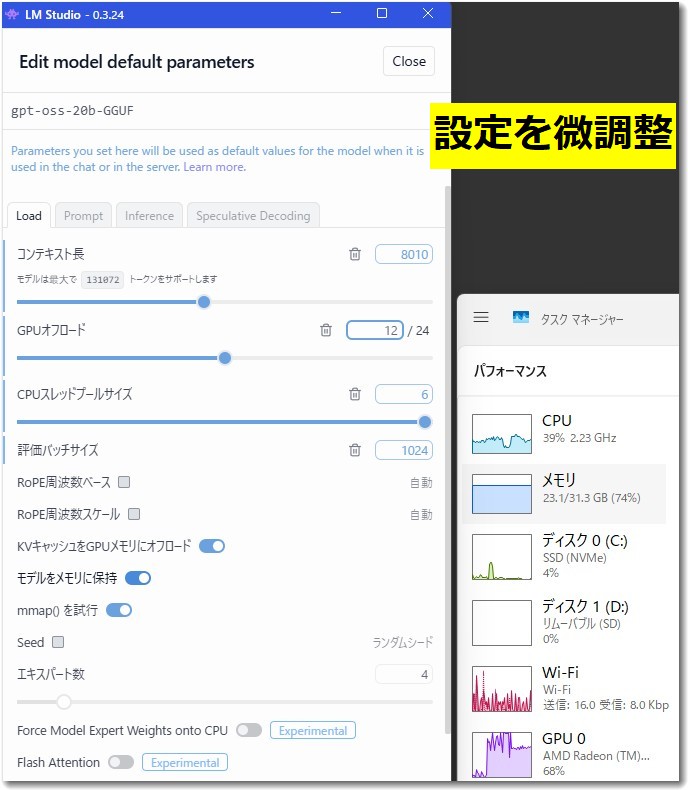
モデル:gpt-oss-20b-GGUF
コンテキスト長:8010→8192に再設定
GPUオフロード:12
CPUスレッドサイズ:6
評価バッチサイズ:
とりあえずこの設定で当面使ってみます。

この記事を書いた遠田幹雄は中小企業診断士です
遠田幹雄は経営コンサルティング企業の株式会社ドモドモコーポレーション代表取締役。石川県かほく市に本社があり金沢市を中心とした北陸三県を主な活動エリアとする経営コンサルタントです。
小規模事業者や中小企業を対象として、経営戦略立案とその後の実行支援、商品開発、販路拡大、マーケティング、ブランド構築等に係る総合的なコンサルティング活動を展開しています。実際にはWEBマーケティングやIT系のご依頼が多いです。
民民での直接契約を中心としていますが、商工三団体などの支援機関が主催するセミナー講師を年間数十回担当したり、支援機関の専門家派遣や中小企業基盤整備機構の経営窓口相談に対応したりもしています。
保有資格:中小企業診断士、情報処理技術者など
会社概要およびプロフィールは株式会社ドモドモコーポレーションの会社案内にて紹介していますので興味ある方はご覧ください。
お問い合わせは電話ではなくお問い合わせフォームからメールにておねがいします。新規の電話番号からの電話は受信しないことにしていますのでご了承ください。

【反応していただけると喜びます(笑)】
記事内容が役にたったとか共感したとかで、なにか反応をしたいという場合はTwitterやフェイスブックなどのSNSで反応いただけるとうれしいです。
本日の段階で当サイトのブログ記事数は 7,121 件になりました。できるだけ毎日更新しようとしています。
遠田幹雄が利用しているSNSは以下のとおりです。
facebook https://www.facebook.com/tohdamikio
ツイッター https://twitter.com/tohdamikio
LINE https://lin.ee/igN7saM
チャットワーク https://www.chatwork.com/tohda

また、投げ銭システムも用意しましたのでお気持ちがあればクレジット決済などでもお支払いいただけます。
※投げ銭はスクエアの「寄付」というシステムに変更しています(2025年1月6日)
※投げ銭は100円からOKです。シャレですので笑ってご支援いただけるとうれしいです(笑)
株式会社ドモドモコーポレーション
石川県かほく市木津ロ64-1 〒929-1171
電話 076-285-8058(通常はFAXになっています)
IP電話:050-3578-5060(留守録あり)
問合→メールフォームからお願いします
法人番号 9220001017731
適格請求書(インボイス)番号 T9220001017731
英語表示の社名:DomoDomo Corporation Inc.

