 AI技術が身近になる中、「自分のパソコンでAIを動かしてみたい」と考える方が増えていますね。私もそのひとりです。
AI技術が身近になる中、「自分のパソコンでAIを動かしてみたい」と考える方が増えていますね。私もそのひとりです。
今回は、NVIDIA GeForce RTX 4060を搭載した新しいパソコンを使い、人気のソフトウェア「LM Studio」で注目度の高いAIモデル「gpt-oss-20b」を快適に動作させるための過程と、最適な設定方法を調べてみました。すでにこのようなモンスターマシンをお持ちの方もこれから購入しようとする方にも参考になるように情報提供します。
NVIDIA GPU搭載PCではじめるローカルAI!LM Studio導入と最適化ガイド
今回の環境:パワフルなDell製タワーPC
今回の対象PCは実際に知人が今月購入したというモンスターマシンです。普通に使うとしたらものすごいスペックなので爆速ですね。
AIをローカル環境で動かすには、ある程度の性能を持つパソコンが必要です。今回使用するPCのスペックは以下の通りです。
- モデル: Dell タワー Plus (EBT2250 4.0 (54))
- プロセッサー: インテル® Core™ Ultra 7 265
- グラフィックス: NVIDIA® GeForce RTX™ 4060 8GB
- メモリ: 32GB DDR5
- ストレージ: 1TB M.2 PCIe NVMe SSD
特に、AIの計算で重要な役割を果たすのがNVIDIA製のGPU「GeForce RTX 4060」です。このGPUの性能を最大限に引き出すことが、快適なAI動作の鍵となります。
最初のステップ:LM StudioでAIモデルを探す
「LM Studio」は、様々なAIモデルを簡単な操作でダウンロードし、実行できる人気のソフトウェアです。無料で商用利用可能なので、興味ある方はぜひダウンロードして使ってみてください。

今回は、OpenAIが公開したオープンソースモデル「gpt-oss-20b」を使ってみます。
LM Studioを起動し、モデル検索画面で「gpt-oss-20b」と入力すると、多数のファイルが表示されます。
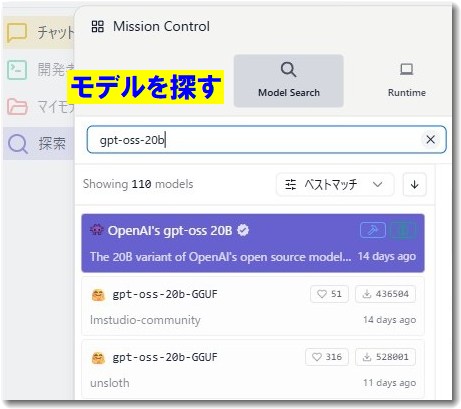
ここで多くの方が戸惑うのが、「同じ名前のファイルがたくさんある」という点です。実は、これらは同じモデルを異なる方法で軽量化したバージョンであり、お使いのPC環境(特にGPUのVRAM容量)に合わせて最適なものを選ぶ必要があります。
【重要ポイント】最適なモデルファイルの選び方
GeForce RTX 4060のVRAMは8GBです。この環境で「gpt-oss-20b」の性能を最大限に引き出すには、以下の3つの条件を満たすファイルを選ぶことが非常に重要です。
- ファイル形式:「GGUF」を選ぶ LM Studioで、CPUとGPU(グラフィックボード)を連携させてAIを効率的に動かすための標準的なファイル形式です。
- 量子化の種類:「MXFP4」を選ぶ【最重要】 AIモデルは通常巨大なため、性能を極力維持したままファイルサイズを小さくする「量子化」という処理がされています。「gpt-oss-20b」は少し特殊な設計のため、「MXFP4」という専用の形式で量子化されたものでないと、性能が大きく低下することがあります。他の「Q4_K_M」といった形式は、このモデルには適していません。
- ファイルサイズ:「約12.1 GB」のものを選ぶ VRAMが8GBの場合、モデルのすべてをGPUに読み込むことができません。ファイルサイズが小さいものを選ぶことで、GPUから溢れてしまう部分を最小限に抑え、処理速度の低下を防ぎます。
今回ダウンロードしたのは、これらの条件をすべて満たしたファイルです。
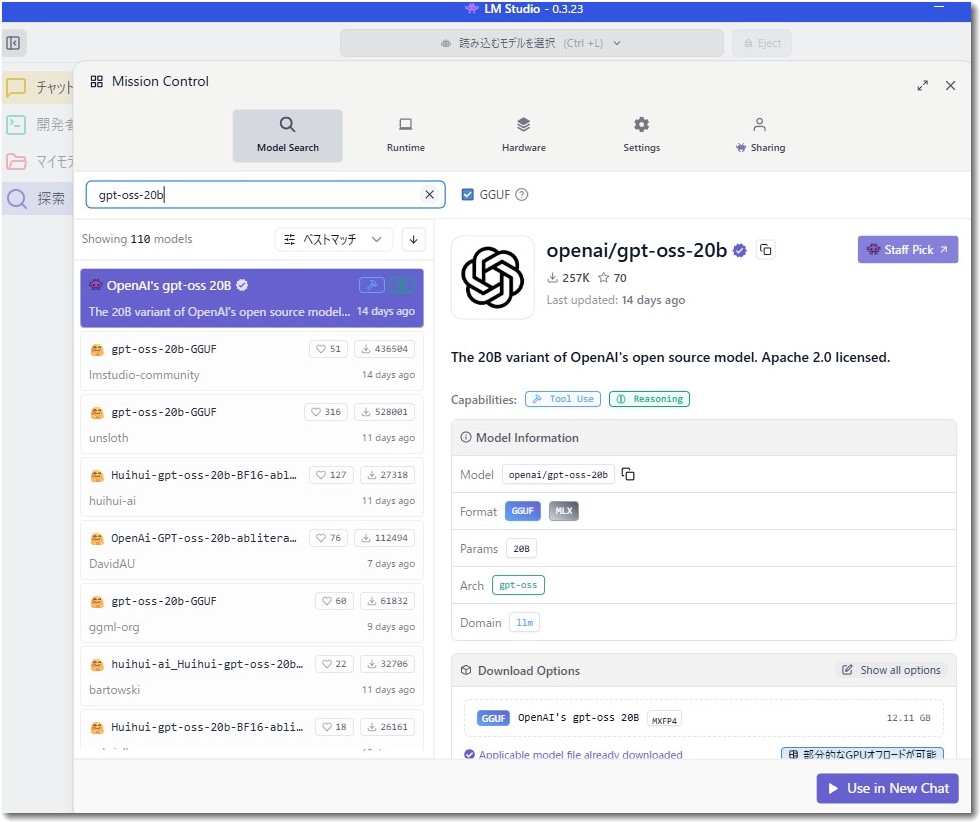
使うモデルは
です。
LMスタジオからモデルを検索すると同じ名前で多数のバージョンがあります。どれを選べばいいかについて、上記の注意点を参考に間違えないように選択してください。皆さんも、ご自身の環境に合わせてファイルを選ぶ際の参考にしてください。
最終設定:GPUの性能を最大限に引き出す
正しいファイルを選んだら、次はLM Studioの設定です。この設定が快適な動作を実現するための最後の仕上げとなります。
- ダウンロードしたモデルの横にある「Use in New Chat」ボタンを押し、チャット画面へ移動します。
- 画面右側に設定パネルが表示されます。ここで「GPU Offload」という項目を探してください。
- 以下の2つの設定を行います。
- 「Force Model Expert Weights onto CPU」をオンにする: これはVRAMが8GBのPCでこのモデルを動かすための最も重要な設定です。AIモデルの特殊な構造の一部をCPUにうまく担当させることで、VRAMの負担を軽減します。
- GPU Offloadスライダーを調整する: スライダーを右に動かし、できるだけ多くの計算をGPUに割り当てます。画面に表示されるVRAM使用量が、お使いのPCの上限(この場合は8GB)に近づくまで調整しましょう(例:7.5GB / 7.9GB)。
以上の設定を行うことで、VRAM 8GBという限られた環境でも、「gpt-oss-20b」を安定して効率的に動作させることができます。
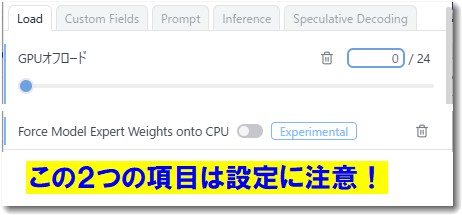
ちなみに上記画像は、私の非力なノートPCの設定画面です。「GPUオフロード」と「Force Model Expert Weights onto CPU」の設定はこのとおりではなく、PCにあわせて最適化してください。
もしVRAMが16GBのPCなら?設定と速度の違い
今回の対象PCは、NVIDIA® GeForce RTX™ 4060 8GBを搭載しているのでVRAMが8GBです。ローカルAIを動作させるならVRAMが重要です。
さらに高性能なGeForce RTX 4070など、VRAMが16GBあるPCを選ぶと、設定はよりシンプルになり、動作も高速になります。
LM Studioの設定の違い
VRAMが16GBあれば、約12.1GBのモデル全体をGPU上に読み込むことが可能です。そのため、設定は以下のように変わります。
出力速度の比較(体感)
では、VRAM容量によって文章が生成される速度はどれくらい違うのでしょうか。インターネット経由で利用するChatGPT-4oとも比較してみましょう。
- VRAM 8GBのローカル環境(今回のPC) 一部の処理をCPUとメインメモリで行うため、GPUだけで処理する場合に比べて速度は遅くなります。文章が少しずつ表示されていくのが分かる速度です。
- VRAM 16GBのローカル環境 モデルのすべての計算が高速なVRAM上で完結するため、8GBの環境と比べて体感で2倍以上速くなることが期待できます。よりスムーズでストレスのない対話が可能です。
- ChatGPT-4o(インターネット経由) 専門のデータセンターにある最高性能のGPUで動作しているため、速度は圧倒的です。インターネットの速度に問題がなければ、回答はほぼ一瞬で表示されます。ただし、プライバシーの観点や、オフラインで使えないといった側面もあります。
ローカルAIの魅力は、プライベートな環境で、インターネット接続なしに使えることです。VRAM容量は、その快適さを大きく左右する要素と言えます。
AIの賢さを調べましょう
LMスタジオでAIモデルを実装したら、その賢さを調べておきましょう。

ちなみに、PCの能力によって回答速度に差がでますが、AIの賢さはPCの能力には関係ありません。遅いPCでもそのモデルが動きさえすれば、そのAIモデルの賢さは維持されます。
まとめ
自分のPCでAIを動かす体験は非常にエキサイティングです。今回のように、少し専門的な知識が必要な場面もありますが、ポイントを押さえれば初心者の方でも十分に楽しむことができます。
- AIモデルは、PCのスペック(特にVRAM)に合った形式・サイズを選ぶ。
- LM Studioのようなツールを使い、GPUオフロード設定を最適化する。
- VRAM容量が大きいほど、設定はシンプルになり、動作はより高速で快適になる。
これらの点を意識して、ぜひ皆さんもローカルAIの世界に挑戦してみてください。
ちなみに、私の現在のPCはマウスコンピューターの非力なノートPCですが、「LMスタジオ」+「gpt-oss-20b」を使っています。
私のノートPCと、今回の対象マシンDell タワー Plus (EBT2250 4.0 (54))との回答速度を比較すると、計算上では1割程度しかありません(泣)

やはり、ローカルAIを実現化するとしたら、それなりのパワーを持ったPCが必要ですね。特にVRAMに注目しましょう。

この記事を書いた遠田幹雄は中小企業診断士です
遠田幹雄は経営コンサルティング企業の株式会社ドモドモコーポレーション代表取締役。石川県かほく市に本社があり金沢市を中心とした北陸三県を主な活動エリアとする経営コンサルタントです。
小規模事業者や中小企業を対象として、経営戦略立案とその後の実行支援、商品開発、販路拡大、マーケティング、ブランド構築等に係る総合的なコンサルティング活動を展開しています。実際にはWEBマーケティングやIT系のご依頼が多いです。
民民での直接契約を中心としていますが、商工三団体などの支援機関が主催するセミナー講師を年間数十回担当したり、支援機関の専門家派遣や中小企業基盤整備機構の経営窓口相談に対応したりもしています。
保有資格:中小企業診断士、情報処理技術者など
会社概要およびプロフィールは株式会社ドモドモコーポレーションの会社案内にて紹介していますので興味ある方はご覧ください。
お問い合わせは電話ではなくお問い合わせフォームからメールにておねがいします。新規の電話番号からの電話は受信しないことにしていますのでご了承ください。

【反応していただけると喜びます(笑)】
記事内容が役にたったとか共感したとかで、なにか反応をしたいという場合はTwitterやフェイスブックなどのSNSで反応いただけるとうれしいです。
本日の段階で当サイトのブログ記事数は 7,109 件になりました。できるだけ毎日更新しようとしています。
遠田幹雄が利用しているSNSは以下のとおりです。
facebook https://www.facebook.com/tohdamikio
ツイッター https://twitter.com/tohdamikio
LINE https://lin.ee/igN7saM
チャットワーク https://www.chatwork.com/tohda

また、投げ銭システムも用意しましたのでお気持ちがあればクレジット決済などでもお支払いいただけます。
※投げ銭はスクエアの「寄付」というシステムに変更しています(2025年1月6日)
※投げ銭は100円からOKです。シャレですので笑ってご支援いただけるとうれしいです(笑)
株式会社ドモドモコーポレーション
石川県かほく市木津ロ64-1 〒929-1171
電話 076-285-8058(通常はFAXになっています)
IP電話:050-3578-5060(留守録あり)
問合→メールフォームからお願いします
法人番号 9220001017731
適格請求書(インボイス)番号 T9220001017731
英語表示の社名:DomoDomo Corporation Inc.

