私たちが自宅や企業で動かす「ローカルAI」の環境は、日々進化を続けています。最近の検証では、「小規模モデルの意外な強さ」を発見しましたが、今回、その常識をさらに塗り替える可能性を秘めた最先端モデル「Gemma-4-e4b-it」を迎え入れました。
私たちが自宅や企業で動かす「ローカルAI」の環境は、日々進化を続けています。最近の検証では、「小規模モデルの意外な強さ」を発見しましたが、今回、その常識をさらに塗り替える可能性を秘めた最先端モデル「Gemma-4-e4b-it」を迎え入れました。
このモデルは、単に「速い」「賢い」というレベルを超えて、非常に洗練された技術的特徴を持っています。今回は、その驚異的なパフォーマンスの裏側にある「スペック」を深掘りし、他の有力候補と比較検証していきます。
ローカルAIで使うモデルにはなにが最適か?
ローカルAIとしてはLMスタジオを利用しています
まずローカルAIの前提条件ですが、私はLMスタジオというソフトウェアを使っています。オープンソースなので無料で使えて、ウインドウズ環境で簡単に利用できます。

このLMスタジオを使い、いろんなAIモデルを試してきました。

昨年の段階でローカルAIは実用レベルに達したと言われています。上記の記事は伝説のプログラマと言われている中嶋聡さんがローカルAIの実用化ということを紹介しています。
🚀 なぜGemma-4-e4b-itが注目されるのか?
「Gemma-4」は2026年4月3日にGoogleから正式に発表されました。

市場には様々なモデルが存在しますが、Gemma-4-e4b-itは、「軽量でありながら高い実用性を持つ」という理想的なバランスを実現しています。特にローカル環境で動かす場合、リソース(メモリやCPU/GPU)の消費量が少ないことは最大のメリットです。
このモデルが持つ具体的な技術仕様をご紹介します。
Gemma-4-e4b-it 詳細スペック解説
| 仕様項目 | 内容 | 解説と意味合い |
|---|---|---|
| Model | qmm4-e4b-it |
モデルの識別名です。軽量版(e4b)であることを示唆しています。 |
| Format | GGUF |
ファイル形式の一つで、効率的な推論実行を可能にするためのフォーマットです。 |
| Quantization | Q4_K_S |
量子化のレベルを示します。 データ量を圧縮しつつ、性能劣化を最小限に抑える高度な手法が適用されています。 |
| Size on disk | 約 6.76 GB | モデルファイル自体のサイズです。 このコンパクトさがローカル運用における大きな強みとなります。 |
| Capabilities | Vision / Tool use |
このモデルは、単なるテキスト生成だけでありません。 画像認識(Vision)や外部ツール連携(Tool use)といった多機能性を持っていることを示しています。 |
このように、Gemma-4-e4b-itは「軽量化(Q4_K_S)」と「高機能化(Vision/Tool use)」を両立させている点が特筆すべき点です。
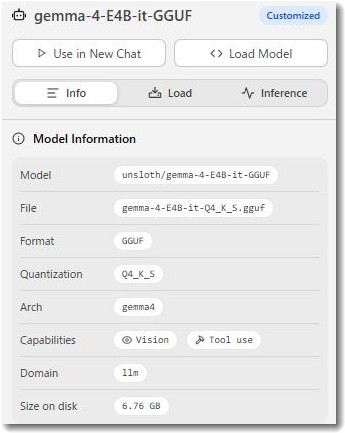
ちなみに、Gemma-4-e4b-itというモデルは画像読み込みが可能です。上記のスペック表はこの画像を読み込ませて記事に挿入するように指示しました。軽量モデルなのに画像のインプットもできるというのは本当にすごいです。
Gemma-4には4つのモデル
ちなみにGemma-4には大きく分けて4つのモデルがあります。
31B Dense:フルスペックの優等生
26B MoE:必要な教科だけ天才家庭教師を呼んでくる
E4B:軽くて燃費良く頭の回転が速い「ポータブル家庭教師」
E2B:スマホにも入る超コンパクトなモデル
私が使っているのは上から3番めの軽量モデルです。これでもかなり実用的です。
最新モデル vs. 旧来の強者たち:比較検証
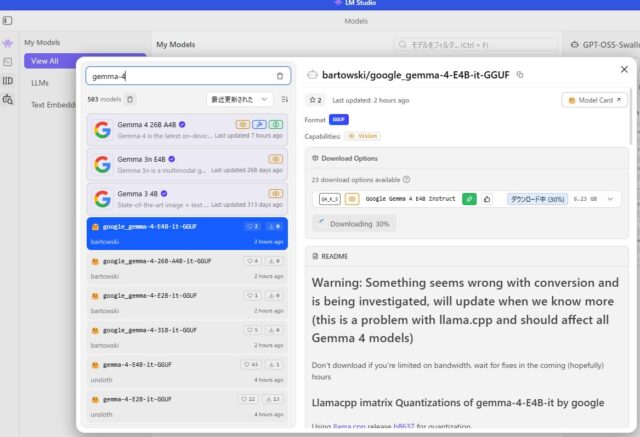
早速、Gemma-4-e4b-itをLMStudioに入れて試してみました。爆速で動いて日本語の回答も自然で本当にすばらしいです。
※実はこのブログ記事の原文はGemma-4-e4b-itで書いています(笑)
このスペックを踏まえ、前回までの知見と比較してみましょう。
NVIDIA 6Bモデルとの対比(質 vs. 速度)
前回の検証でNVIDIA 6Bが日本語生成の「自然さ」で優位性を見せましたが、Gemma-4-e4b-itは、その高い品質を維持しつつ、応答速度において圧倒的なアドバンテージを持ちます。もしあなたが「完璧な文章作成」よりも「リアルタイムでの質の高い対話」を求めるなら、Gemma-4が強力な選択肢となります。

大規模モデル(GPT/OSS 20B)との対比(知識量 vs. 実用性)
もちろん、巨大なモデルは膨大な知識を持っていますが、その分、動作には大きなリソースを要求します。Gemma-4-e4b-itは、この「大規模モデルの知性を、極限まで軽量化して実用レベルに落とし込んだ」成功例と言えるでしょう。
🎯 まとめ:あなたのAI体験を最適化する選択肢
今回の検証で明らかになったのは、「最強のAI」という概念が、「何を優先するか」によって定義されるということです。
✅ 最高の日本語表現力と完成度を求めるなら NVIDIA 6Bのような特定モデルを深掘りする。
✅ 圧倒的な速度と多機能性(画像・ツール連携)を求めるなら Gemma-4-e4b-itが現在の最有力候補です!
✅ 知識の網羅性と汎用性を追求するなら 大規模モデルのリソース投入が必要。
ローカルAIは、もはや「試す」段階から「最適化する」段階へと移行しています。Gemma-4-e4b-itのような最先端の軽量モデルを理解し活用することは、私たちクリエイターや開発者にとって大きな武器となります。
ちなみに「Gemma-4-e4b-it」は軽量モデルなのでノートPCでも動きます。速度は少しゆっくりめですが実用レベルです。
上記のGPUコンピュータだと爆速でした。瞬時に回答が走るという体験を味わうともう遅い環境に戻れませんね。

この「Gemma-4-e4b-it」をベースとして、ブラウザで簡単に使える「ローカルAI」環境を強化しました。100万行のCSVファイルの計算もできるようになりました。ローカルAI強化については上記の記事をご覧ください。

この記事を書いた遠田幹雄は中小企業診断士です
遠田幹雄は経営コンサルティング企業の株式会社ドモドモコーポレーション代表取締役。石川県かほく市に本社があり金沢市を中心とした北陸三県を主な活動エリアとする経営コンサルタントです。
小規模事業者や中小企業を対象として、経営戦略立案とその後の実行支援、商品開発、販路拡大、マーケティング、ブランド構築等に係る総合的なコンサルティング活動を展開しています。実際にはWEBマーケティングやIT系のご依頼が多いです。
民民での直接契約を中心としていますが、商工三団体などの支援機関が主催するセミナー講師を年間数十回担当したり、支援機関の専門家派遣や中小企業基盤整備機構の経営窓口相談に対応したりもしています。
保有資格:中小企業診断士、情報処理技術者など
会社概要およびプロフィールは株式会社ドモドモコーポレーションの会社案内にて紹介していますので興味ある方はご覧ください。
お問い合わせは電話ではなくお問い合わせフォームからメールにておねがいします。新規の電話番号からの電話は受信しないことにしていますのでご了承ください。

【反応していただけると喜びます(笑)】
記事内容が役にたったとか共感したとかで、なにか反応をしたいという場合はTwitterやフェイスブックなどのSNSで反応いただけるとうれしいです。
本日の段階で当サイトのブログ記事数は 7,104 件になりました。できるだけ毎日更新しようとしています。
遠田幹雄が利用しているSNSは以下のとおりです。
facebook https://www.facebook.com/tohdamikio
ツイッター https://twitter.com/tohdamikio
LINE https://lin.ee/igN7saM
チャットワーク https://www.chatwork.com/tohda

また、投げ銭システムも用意しましたのでお気持ちがあればクレジット決済などでもお支払いいただけます。
※投げ銭はスクエアの「寄付」というシステムに変更しています(2025年1月6日)
※投げ銭は100円からOKです。シャレですので笑ってご支援いただけるとうれしいです(笑)
株式会社ドモドモコーポレーション
石川県かほく市木津ロ64-1 〒929-1171
電話 076-285-8058(通常はFAXになっています)
IP電話:050-3578-5060(留守録あり)
問合→メールフォームからお願いします
法人番号 9220001017731
適格請求書(インボイス)番号 T9220001017731
英語表示の社名:DomoDomo Corporation Inc.