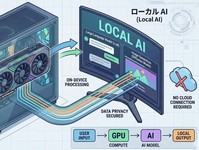
 今回はローカルAIについての報告です。ローカルで大規模言語モデル(LLM)を快適に動かすための基盤作りとして、新しくPCを導入しました。
今回はローカルAIについての報告です。ローカルで大規模言語モデル(LLM)を快適に動かすための基盤作りとして、新しくPCを導入しました。
そして、これまでノートPCで細々と動かしていた「LM Studio」を本格運用すべく、複数の最新モデルをテストした結果を備忘録としてまとめます。
サクサク使えるローカルAIの環境ができました
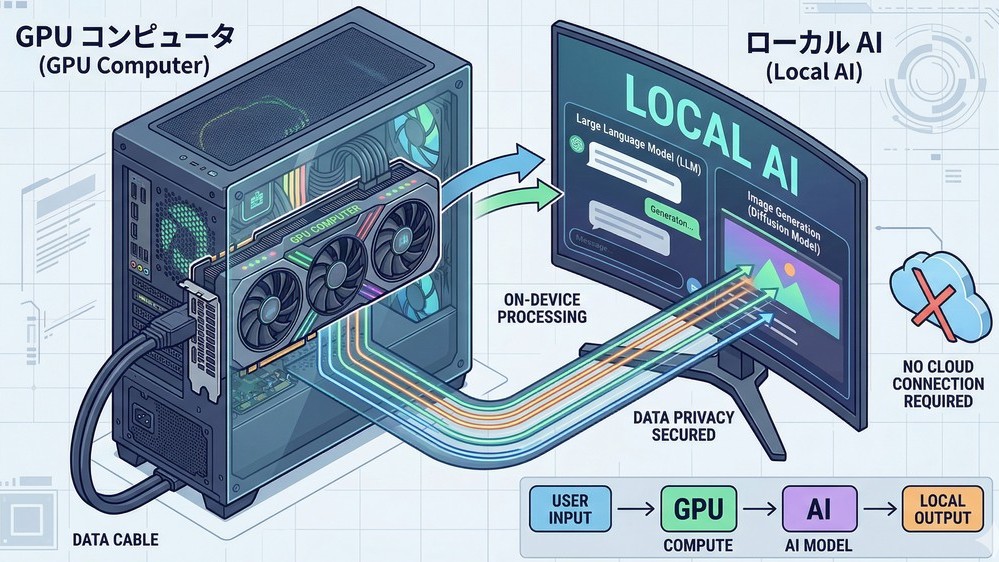
導入したハードウェアと環境
ローカルLLMの性能はグラフィックボードの「VRAM(ビデオメモリ)容量」に大きく依存するため、今回はVRAM 16GBを搭載したPCを新調しました。
で、自分としては過去最大級の投資です。
以下製品のスペックです
【製品名 GALLERIA XPR7M-R57T-GD】
CPU AMD Ryzen 7 7700(3.8GHz〜5.3GHz / 8コア / 16スレッド)
OS Windows 11 Pro 64ビット
サウンド マザーボード標準 オンボードHDサウンド
メモリ 32GB(16GB×2)DDR5-4800
マザーボード AMD A620A チップセット マイクロATX
グラフィック NVIDIA GeForce RTX 5070 Ti 16GB GDDR7
映像出力:HDMI×1、DisplayPort×3
LAN 2.5Gb対応LANポート×1(オンボード)
ケース ガレリア専用 GEm-Gケース(MicroATX)ガンメタル × ダークグレイ
電源 750W(80PLUS GOLD)
CPUファン 水冷 Asetek 624S-M2(240mm / 非発光)
ストレージ 2TB SSD(NVMe Gen4)
Wi-Fi 6 + Bluetooth 5.2
入出力ポート
前面:
・USB2.0 ×2
・USB3.2 Gen1 Type-A ×2
・USB3.2 Gen1 Type-C ×1
背面:
・USB2.0 ×2
・USB3.2 Gen1 Type-A ×2
・映像出力 HDMI ×1、DisplayPort ×1

AIモデルの比較検討
使用ソフト: LM Studio
主な用途: 業務におけるレポート作成、議事録の要約など(文章生成メイン)
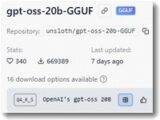
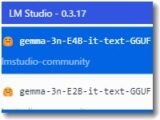
これまでノートPCで利用してきたのは上記のような感じです。非力なノートPCなので小さなモデルでしか使えませんでした。
今回のPCはハイスペックです。このVRAM 16GBの恩恵を活かすため、今回はこれまで使えなかった大型モデルを中心に以下のモデルをテストしました。
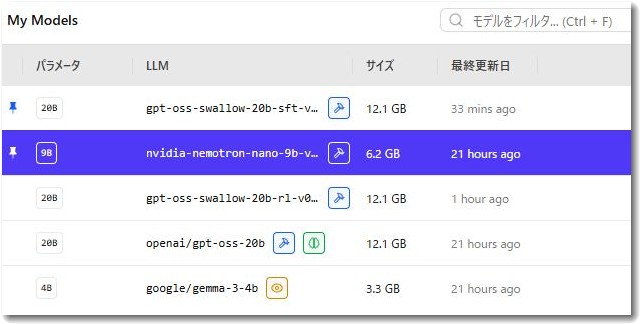
検証したモデル(GGUF形式)
GPT-OSS 20B (Standard)
パラメータ数:200億 (20B) / VRAM消費目安:約12.1GB
GPT-OSS Swallow 20B (RL版 / SFT版)
パラメータ数:200億 (20B) / VRAM消費目安:約12.1GB
※東京科学大学(旧・東工大)と産総研が日本語推論能力を強化した特化モデル
NVIDIA Nemotron Nano 9B v2 Japanese
パラメータ数:90億 (9B) / VRAM消費目安:約6.2GB
テスト経過と所感
驚異的な生成スピード、しかし日本語の精度に課題(GPT-OSS 20B)
まずベースとなる「GPT-OSS 20B」をテストしました。驚いたのはその生成速度です。新しいGPU(RTX 5070 Ti)の恩恵で、200億パラメータの大型モデルにも関わらず爆速でテキストを出力してくれました。
しかし、レポート作成など実務の文章生成に組み込んでみると、日本語の言い回しやニュアンスがいまひとつ「しっくりこない」場面が散見されました。
日本語特化の推論モデルへの期待と現実(GPT-OSS Swallow 20B)
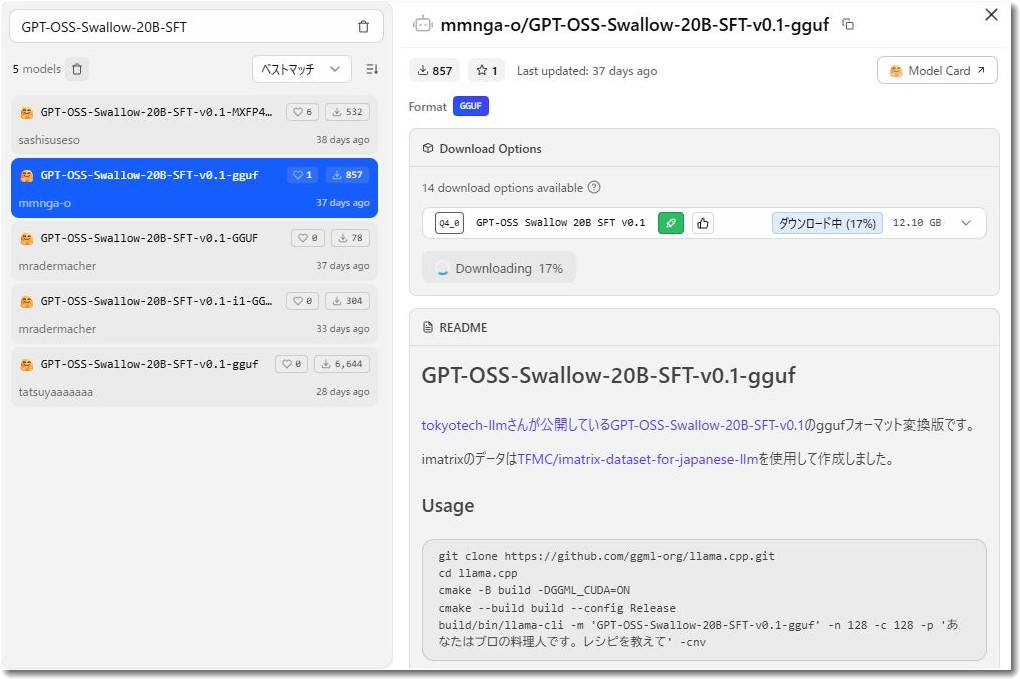
そこで、最近AI界隈で「日本語推論に強い」と好成績を出している、東京科学大学(旧・東工大)チューニングの「GPT-OSS Swallow 20B」シリーズをテストしました。
論理的思考に特化した「RL(強化学習)版」や、安定志向の「SFT版」などを試しましたが、私の求めるレポート・議事録作成の用途においては、期待したほどの劇的な成果は得られませんでした。システムプロンプトでの制御がうまく効かない点もありちょっと残念な感じになってしまいました。
結論:圧倒的なバランスを誇る「NVIDIA 9B」が優勝
最終的に最も実用的だったのが、NVIDIAの「Nemotron Nano 9B v2 Japanese」でした。
パラメータサイズは9B(20Bの半分以下)と小型ですが、最新の学習手法が用いられているためか、出力される日本語の質が最も高く、私の用途にベストマッチしました。
さらに、このモデルを採用する最大のメリットは「VRAMの余裕」です。
・GPToss20Bモデル: VRAMを12GB以上消費するため、AIの記憶領域(コンテキスト長)を「8,192 (8K)」程度に抑えないと動作が不安定になります。
・NVIDIA 9B: VRAM消費が約6.2GBで済むため、コンテキスト長を「16,384 (16K)」と2倍に広げても全く問題なくサクサク動作すします。
長い議事録を読み込ませたり、文脈を維持したまま対話を続ける上で、この「コンテキスト長16Kを常時使える」という点は、使い勝手を劇的に向上させてくれました。
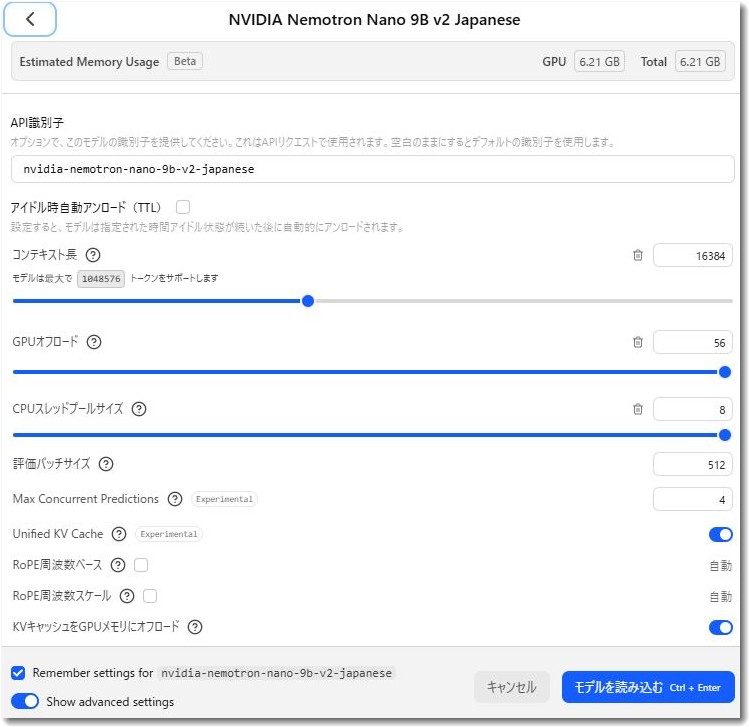
NVIDIAの「Nemotron Nano 9B v2 Japanese」の回答例
実際にLMスタジオのNVIDIAの「Nemotron Nano 9B v2 Japanese」で回答させた例を紹介します。入力は音声入力なので少し不自然ですが、回答はちゃんとしています。生成速度も10.7秒なので実用的です。

ローカル環境でLMスタジオを活用し、複数の言語モデルを実践的にテストした結果、予想外の成果が得られました。今回重点的に検証したのは、GPT系の汎用モデルや大規模なOSS 20Bを含む候補群でしたが、その中でも際立ったパフォーマンスを示したのはNVIDIA開発の6Bモデルでした。
特に日本語生成においては、単なる計算能力ではなく「言語特性への最適化」が鍵だったと考えます。大型モデルでは時に過剰な情報処理による不自然さが目立つ中、6Bモデルは文脈理解と出力精度のバランスが非常に優れており、日本語特有の表現ニュアンスや助詞の配置まで丁寧に再現していました。また、ローカル環境での動作効率も良好で、高速なレスポンスと安定した品質を両立している点が実用的な強みです。
この結果を踏まえると、日本語対応を重視するシナリオでは「スケール」ではなく「最適化の精度」が重要であることが改めて浮き彫りになりました。今後はさらに日本語専用チューニング版の開発も期待したいところです。
ローカル環境での実験を通じて、高品質な生成モデル選定には「条件に合わせた適正サイズ」が不可欠であることを改めて学びました。この経験を多くの開発者に共有し、より効率的なAI活用を促していきたいと思います。
エディタ連携(VS Code)に関する課題
今回、プロンプトの管理や作業効率化のために「VS Code(Continue拡張機能)」との連携も試し始めました。LMスタジオでモデルを設定してローカルで解放するとVSコードの画面から使えるようになります。たしかにこれは便利。
しかし、推論モデル(RL版など)が内部で出力する「思考プロセス」のテキストがVS Code側でパースエラーを引き起こすなど、LM Studioとの連携においていくつか挙動問題を起こしました。
ツール間の相性問題でストレスを抱えるよりは、純粋な生成精度と速度を活かすため、当面はLM Studio本体のチャット画面だけでシンプルに運用していく方針とします。文章生成だけであればこの運用がベターだと思います。
なお、今後、他の使い方も検討しているので、その状況になればまた設定を変えていくかもしれません。
ローカルAI環境がスタートできました

ローカルLLMは「パラメータサイズが大きければ良い」というわけではありませんね。
「VRAMに十分な余裕を持たせ、高品質な中型モデル(9Bクラス)を広いコンテキスト長(16K)で回す」のが、現在のRTX 5070 Ti環境における最適解だと実感しました。
また新たなモデルがでたりメモリ圧縮の新技術などもでたりするでしょうから、環境変化に適合させて使っていきたいと思います。
※このPCのGPUは「5070 Ti」です。これまで「5060 Ti」という表現と混在していましたが、購入時のスペックを再確認して「5070 Ti」であることが確認できたので修正しました。
ブラウザで使えるローカルAI環境に進化しました
LMスタジオ単体ではできないこともできるようにしました。

ローカルAI環境を見直しブラウザで使えるようにしたことで、4万行のCSV分析まで回せるようになりました。理論上は100万行の処理も可能です。
ローカルAIの関連記事
▼LMスタジオやAIモデル関連の記事

▼ローカルAI関連の記事

ローカルAI関係の記事をまとめましたので関連記事もご覧ください。

この記事を書いた遠田幹雄は中小企業診断士です
遠田幹雄は経営コンサルティング企業の株式会社ドモドモコーポレーション代表取締役。石川県かほく市に本社があり金沢市を中心とした北陸三県を主な活動エリアとする経営コンサルタントです。
小規模事業者や中小企業を対象として、経営戦略立案とその後の実行支援、商品開発、販路拡大、マーケティング、ブランド構築等に係る総合的なコンサルティング活動を展開しています。実際にはWEBマーケティングやIT系のご依頼が多いです。
民民での直接契約を中心としていますが、商工三団体などの支援機関が主催するセミナー講師を年間数十回担当したり、支援機関の専門家派遣や中小企業基盤整備機構の経営窓口相談に対応したりもしています。
保有資格:中小企業診断士、情報処理技術者など
会社概要およびプロフィールは株式会社ドモドモコーポレーションの会社案内にて紹介していますので興味ある方はご覧ください。
お問い合わせは電話ではなくお問い合わせフォームからメールにておねがいします。新規の電話番号からの電話は受信しないことにしていますのでご了承ください。

【反応していただけると喜びます(笑)】
記事内容が役にたったとか共感したとかで、なにか反応をしたいという場合はTwitterやフェイスブックなどのSNSで反応いただけるとうれしいです。
本日の段階で当サイトのブログ記事数は 7,101 件になりました。できるだけ毎日更新しようとしています。
遠田幹雄が利用しているSNSは以下のとおりです。
facebook https://www.facebook.com/tohdamikio
ツイッター https://twitter.com/tohdamikio
LINE https://lin.ee/igN7saM
チャットワーク https://www.chatwork.com/tohda

また、投げ銭システムも用意しましたのでお気持ちがあればクレジット決済などでもお支払いいただけます。
※投げ銭はスクエアの「寄付」というシステムに変更しています(2025年1月6日)
※投げ銭は100円からOKです。シャレですので笑ってご支援いただけるとうれしいです(笑)
株式会社ドモドモコーポレーション
石川県かほく市木津ロ64-1 〒929-1171
電話 076-285-8058(通常はFAXになっています)
IP電話:050-3578-5060(留守録あり)
問合→メールフォームからお願いします
法人番号 9220001017731
適格請求書(インボイス)番号 T9220001017731
英語表示の社名:DomoDomo Corporation Inc.

